البحث في الموقع
Showing results for tags 'classification'.
تم العثور علي 2 نتائج
-
اذا لدينا مجموعة من البيانات و ليكن عددها 394 قراءة مثلا و نود تصنيفها الي مجموعات و مطلوب استنتاج عدد المجموعات و مجال كل منها فان احدى الطرق المفيدة هي طريقة two to the k rule طريقة 2 أس K وفيها نبحث عن أكبر K ممكنة بحيث تكون 2 أس K أقل من عدد القراءات ففي حالة مثالنا هنا 2 أس 8 = 256 (أقل من عدد السجلات الذي هو 394) مقبول و 2 أس 9 = 512 (أكبر من عدد السجلات الذي هو 394) يرفض اذا تكون K = 8 أي أن لدينا 8 مجموعات و الان نريد معرفة نطاق هذه المجموعات الثمانية Interval = (H-L)/ K أي محسب الفرق بين أكبر قراءة و أضغر قراءة ثم نقسمه علي K مثلا لو كانت اكبر قراءة = 900 و اضغر قراءة = 50 فيكون سعة المجموعة = 106.25 على الاقل ، فيتم التقريب الي 110 و بذلك تكون المجموعات الثمانية كما يلي: From To 1 50 160 2 160 270 3 270 380 4 380 490 5 490 600 6 600 710 7 710 820 8 820 930 Clustering-Intervals rule.xlsx
-
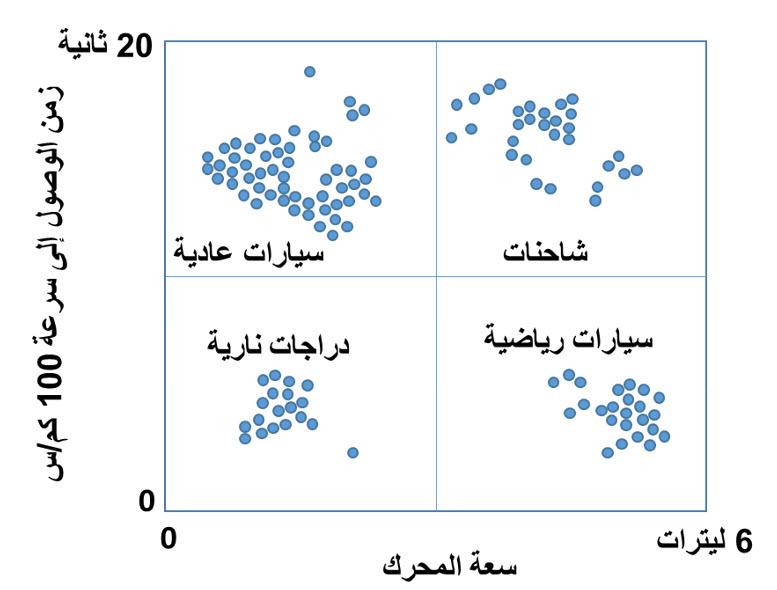
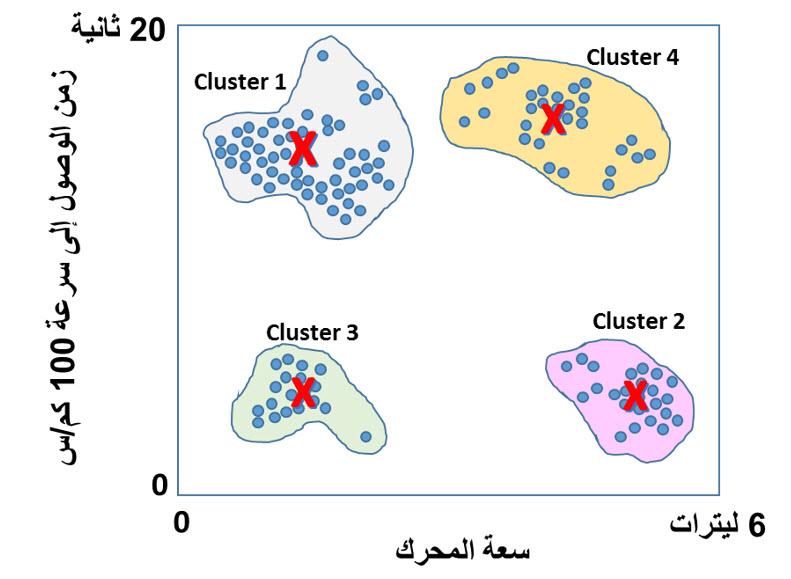
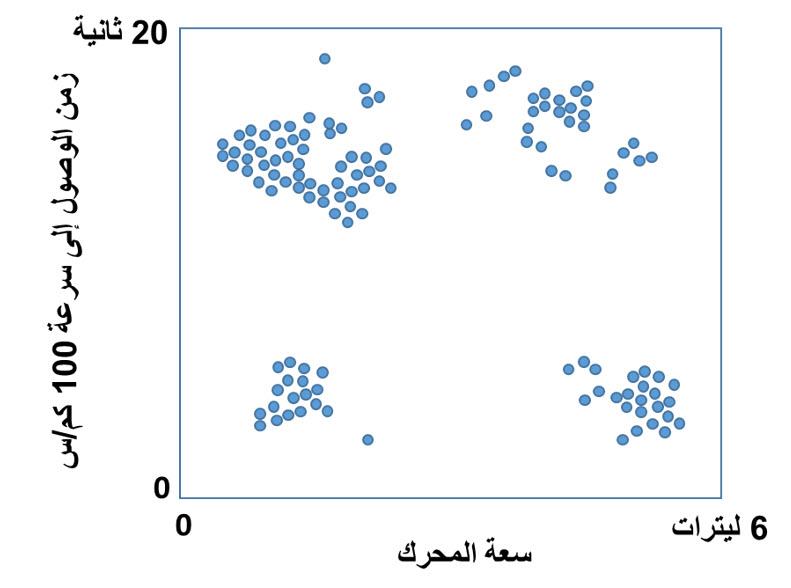
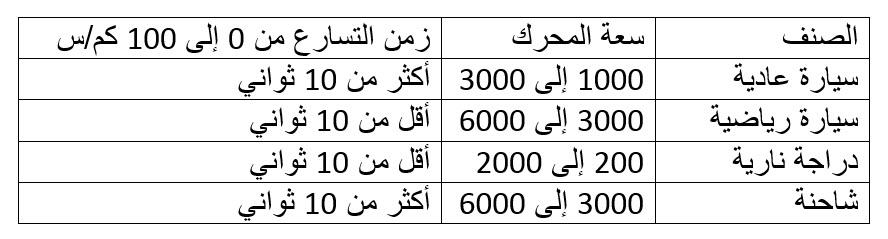
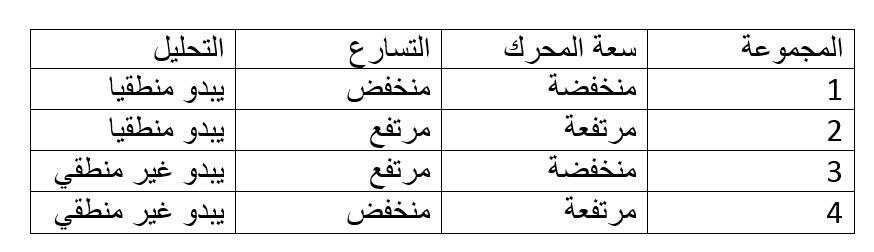
اخترت أسلوبين لتحليل البيانات لشرحهما والمقارنة بنيهما، والأسلوبين هما التجميع Clustering والتصنيف Classification، والسبب لاختياري هذين الأسلوبين أنني كنت محتار تماما في الفرق بينهما، وبالتالي قرأت عنهما الكثير وتوصلت لفهم بسيط لكل منهما والفرق الأساسي بينهما، ولكي أشرحهما سأقوم باستعراض مثال بسيط معكم. تخيل أنك لا تعرف شيء عن المركبات أو السيارات، وتم إعطائك مجموعة كبيرة من البيانات Big Data عن المركبات التي تسير في شوارع مدينتك، وكانت هذه البيانات في صورة جدول يتضمن سعة المحرك باللتر، والزمن الذي تستغرقه المركبة للوصول إلى سرعة 100 كيلومتر/الساعة بالثانية، كما يوضح الرسم البياني أدناه تذكر أنك لا تعرف شيء عن المركبات، ولا تستطيع أن تحدد نوع المركبة، أو حجمها من البيانات المتاحة، ولكن مطلوب منك تحليل البيانات ومحاولة إيجاد علاقات منطقية بينها. هل تستخدم التجميع Clustering أم التصنيف Classification ؟ من المنطقي في هذه الحالة ألا تحاول استخدام التصنيف، فأنت لا تعرف الأصناف الموجودة ومواصفات كل منها، وهذه هي نفس المشكلة التي سيواجهها جهاز الحاسب الآلي الذي يستطيع معالجة البيانات بسرعة ولكن ليس لديه فهم مسبق عن ماهية البيانات. وبالتالي يصبح حتميا استخدام التجميع Clustering، وهو عبارة عن تجميع البيانات القريبة من بعضها البعض في مجموعة واحدة Cluster، وإيجاد المتوسط الحسابي لها بحيث تكون النقاط المشمولة في المجموعة أقرب للمتوسط الحسابي للمجموعة الخاصة بها من المتوسط الحسابي لأي مجموعة أخرى، كما يوضح الشكل أدناه. والسؤال الآن، ما الذي استفدناه من هذا التجميع؟ دعونا أولا نسجل بعض الملاحظات عن المجموعات الأربعة التي ظهرت لدينا: - المجموعة 1 تتضمن أكبر عدد من النقاط وتتميز بانخفاض سعة المحرك وارتفاع زمن الوصول إلى 100 كيلومتر/الساعة (أي انخفاض القدرة على التسارع) - المجموعة 2 تتضمن تقريبا أقل عدد من النقاط وتتميز بارتفاع سعة المحرك وانخفاض زمن الوصول إلى 100 كيلومتر/الساعة (أي ارتفاع القدرة على التسارع) - المجموعة 3 تتضمن عدد قليل من النقاط وتتميز بانخفاض سعة المحرك وانخفاض زمن الوصول إلى 100 كيلومتر/الساعة (أي ارتفاع القدرة على التسارع) - المجموعة 4 تتضمن عدد متوسط من النقاط وتتميز بارتفاع سعة المحرك وارتفاع زمن الوصول إلى 100 كيلومتر/الساعة (أي انخفاض القدرة على التسارع) دعونا نقوم بتحليل هذه النتائج من وجهة النظر المنطقية: نفترض الآن أنك تريد أن تفهم أسباب منطقية وعدم منطقية النتائج، طبعا ستلجأ لصديق يفهم جيدا في أنواع المركبات وأصنافها، وسيكون رده في الغالب كما يلي: · المجموعة 1 ذات سعة المحرك المنخفضة والتسارع المنخفض هي السيارات العادية Passenger Vehicles · المجموعة 2 ذات سعة المحرك المرتفعة والتسارع المرتفع هي السيارات الرياضية Sports Cars · المجموعة 3 ذات سعة المحرك المنخفضة والتسارع المرتفعة هي الدراجات النارية Motor Cycles · المجموعة 4 ذات سعة المحرك المرتفعة والتسارع المنخفض هي الشاحنات Trucks إذن التجميع لا يبدأ بتصنيفات محددة ولكنه يصل إلى الأصناف من خلال التجميع والتحليل، وطبعا في هذا المثال لم نصل إلى أي اكتشافات أو أنماط جديدة لأننا تطرقنا إلى موضوع مفهوم مسبقا وتصنيفاته معروفة، ولكن فائدة التجميع تظهر في تحليل البيانات غير محددة التصنيف. فعلى سبيل المثال لو توفرت لديك معلومات عن أعمار المتسوقين وأنواع المشروبات التي يشترونها، يمكنك تجميعها في مجموعات تحدد من خلالها إذا ما كان العمر يؤثر على اختيار المشروب، ونوعية المشروب المفضل لفئات عمرية محددة، وبالتالي يتم توجيه المواد الإعلانية للأشخاص طبقا لاختياراتهم المسبقة. دعونا الآن نتطرق إلى التصنيف، وسنستخدم نفس مثال المركبات، في هذه الحالة قبل أن تبدأ في تحليل البيانات ستسأل صديقك خبير المركبات عن الأصناف المختلفة للمركبات، وفي الغالب سيعطيك جدول بالأصناف المختلفة كما يلي: وستقوم بناء على هذه الجدول تصنيف المركبات إلى الأصناف الأربعة كما يوضح الرسم التالي: أو بمعني آخر العيب الرئيسي للتصنيف أنه قد يمنعك من اكتشاف علاقات جديدة بين البيانات أرجو أن أكون قد تمكنت من توضيح الفرق بين التجميع والتصنيف، والله ولي التوفيق دائما